This challenge is for developers interested in designing, building, testing, and maintaining cloud applications and services on Microsoft Azure.
Explore Azure App Service
Examine Azure App Service
Azure App Service is an HTTP-based service for hosting web applications, REST APIs, and mobile back ends. You can develop in your favorite language, be it .NET, .NET Core, Java, Ruby, Node.js, PHP, or Python. Applications run and scale with ease on both Windows and Linux-based environments.
Built-in auto scale support
Depending on the usage of the web app, you can scale your app up/down the resources of the underlying machine that is hosting your web app. Resources include the number of cores or the amount of RAM available. Scaling out/in is the ability to increase, or decrease, the number of machine instances that are running your web app.
Continuous integration/deployment support
The Azure portal provides out-of-the-box continuous integration and deployment with Azure DevOps, GitHub, Bitbucket, FTP, or a local Git repository on your development machine. Connect your web app with any of the above sources and App Service will do the rest for you by auto-syncing code and any future changes on the code into the web app.
Deployment slots
Using the Azure portal, or command-line tools, you can easily add deployment slots to an App Service web app. For instance, you can create a staging deployment slot where you can push your code to test on Azure. Once you are happy with your code, you can easily swap the staging deployment slot with the production slot.
Examine Azure App Service plans
In App Service, an app (Web Apps, API Apps, or Mobile Apps) always runs in an App Service plan. An App Service plan defines a set of compute resources for a web app to run. One or more apps can be configured to run on the same computing resources (or in the same App Service plan).
How does my app run and scale
In the Free and Shared tiers, an app receives CPU minutes on a shared VM instance and can’t scale out. In other tiers, an app runs and scales as follows:
- An app runs on all the VM instances configured in the App Service plan.
- If multiple apps are in the same App Service plan, they all share the same VM instances.
- If you have multiple deployment slots for an app, all deployment slots also run on the same VM instances.
- If you enable diagnostic logs, perform backups, or run WebJobs, they also use CPU cycles and memory on these VM instances.
In this way, the App Service plan is the scale unit of the App Service apps. If the plan is configured to run five VM instances, then all apps in the plan run on all five instances. If the plan is configured for autoscaling, then all apps in the plan are scaled out together based on the autoscale settings.
What if my app needs more capabilities or features?
Your App Service plan can be scaled up and down at any time. It is as simple as changing the pricing tier of the plan. If your app is in the same App Service plan with other apps, you may want to improve the app’s performance by isolating the compute resources. You can do it by moving the app into a separate App Service plan.
Deploy to App Service
Every development team has unique requirements that can make implementing an efficient deployment pipeline difficult on any cloud service. App Service supports both automated and manual deployment.
Automated deployment
Automated deployment, or continuous integration, is a process used to push out new features and bug fixes in a fast and repetitive pattern with minimal impact on end users.
Azure supports automated deployment directly from several sources.
- Azure DevOps
- GitHub
- Bitbucket
Manual deployment
There are a few options that you can use to manually push your code to Azure:
- Git
- CLI
- Zip deploy
- FTP/S
Use deployment slots
Whenever possible, use deployment slots when deploying a new production build. When using a Standard App Service Plan tier or better, you can deploy your app to a staging environment and then swap your staging and production slots. The swap operation warms up the necessary worker instances to match your production scale, thus eliminating downtime.
Explore authentication and authorization in App Service
Azure App Service provides built-in authentication and authorization support, so you can sign in users and access data by writing minimal or no code in your web app, API, and mobile back end, and also Azure Functions.
Identity providers
App Service uses federated identity, in which a third-party identity provider manages the user identities and authentication flow for you. The following identity providers are available by default:
| Provider | Sign-in endpoint | How-To guidance |
|---|---|---|
| Microsoft Identity Platform | /.auth/login/aad | App Service Microsoft Identity Platform login |
| /.auth/login/facebook | App Service Facebook login | |
| /.auth/login/google | App Service Google login | |
| /.auth/login/twitter | App Service Twitter login |
How it works
The authentication and authorization module runs in the same sandbox as your application code. When it’s enabled, every incoming HTTP request passes through it before being handled by your application code. This module handles several things for your app:
- Authenticates users with the specified provider
- Validates, stores, and refreshes tokens
- Manages the authenticated session
- Injects identity information into request headers
Authentication flow
Explore Azure Functions
Discover Azure Functions
Azure Functions are a great solution for processing data, integrating systems, working with the internet-of-things (IoT), and building simple APIs and microservices. Consider Functions for tasks like image or order processing, file maintenance, or for any tasks that you want to run on a schedule.
Compare Azure Functions and Azure Logic Apps
Both Functions and Logic Apps enable serverless workloads. Azure Functions is a serverless compute service, whereas Azure Logic Apps provides serverless workflows. Both can create complex orchestrations.
For Azure Functions, you develop orchestrations by writing code and using the Durable Functions extension. For Logic Apps, you create orchestrations by using a GUI or editing configuration files.
You can mix and match services when you build an orchestration, calling functions from logic apps and calling logic apps from functions.
| Durable Functions | Logic Apps | |
|---|---|---|
| Development | Code-first (imperative) | Designer-first (declarative) |
| Connectivity | About a dozen built-in binding types, write code for custom bindings | Large collection of connectors, Enterprise Integration Pack for B2B scenarios, build custom connectors |
| Actions | Each activity is an Azure function; write code for activity functions | Large collection of ready-made actions |
| Monitoring | Azure Application Insights | Azure portal, Azure Monitor logs |
| Management | REST API, Visual Studio | Azure portal, REST API, PowerShell, Visual Studio |
| Execution context | Can run locally or in the cloud | Runs only in the cloud |
Compare Functions and WebJobs
Like Azure Functions, Azure App Service WebJobs with the WebJobs SDK is a code-first integration service that is designed for developers. Both are built on Azure App Service and support features such as source control integration, authentication, and monitoring with Application Insights integration.
Azure Functions is built on the WebJobs SDK, so it shares many of the same event triggers and connections to other Azure services.
| Functions | WebJobs with WebJobs SDK | |
|---|---|---|
| Serverless app model with automatic scaling | Yes | No |
| Develop and test in browser | Yes | No |
| Pay-per-use pricing | Yes | No |
| Integration with Logic Apps | Yes | No |
| Trigger events | Timer Azure Storage queues and blobs Azure Service Bus queues and topics Azure Cosmos DB Azure Event Hubs HTTP/WebHook (GitHub Slack) Azure Event Grid | Timer Azure Storage queues and blobs Azure Service Bus queues and topics Azure Cosmos DB Azure Event Hubs File system |
Compare Azure Functions hosting options
There are three basic hosting plans available for Azure Functions: Consumption plan, Functions Premium plan, and App service (Dedicated) plan.
The following is a summary of the benefits of the three main hosting plans for Functions:
| Plan | Benefits |
|---|---|
| Consumption plan | This is the default hosting plan. It scales automatically and you only pay for compute resources when your functions are running. Instances of the Functions host are dynamically added and removed based on the number of incoming events. |
| Functions Premium plan | Automatically scales based on demand using pre-warmed workers which run applications with no delay after being idle, runs on more powerful instances, and connects to virtual networks. |
| App service plan | Run your functions within an App Service plan at regular App Service plan rates. Best for long-running scenarios where Durable Functions can’t be used. |
Always on
If you run on an App Service plan, you should enable the Always on setting so that your function app runs correctly. On an App Service plan, the functions runtime goes idle after a few minutes of inactivity, so only HTTP triggers will “wake up” your functions. Always on is available only on an App Service plan.
Storage account requirements
On any plan, a function app requires a general Azure Storage account, which supports Azure Blob, Queue, Files, and Table storage. This is because Functions relies on Azure Storage for operations such as managing triggers and logging function executions, but some storage accounts do not support queues and tables.
Scale Azure Functions
In the Consumption and Premium plans, Azure Functions scales CPU and memory resources by adding additional instances of the Functions host. The number of instances is determined on the number of events that trigger a function.
Runtime scaling
Azure Functions uses a component called the scale controller to monitor the rate of events and determine whether to scale out or scale in. The scale controller uses heuristics for each trigger type. For example, when you’re using an Azure Queue storage trigger, it scales based on the queue length and the age of the oldest queue message.
The unit of scale for Azure Functions is the function app. When the function app is scaled out, additional resources are allocated to run multiple instances of the Azure Functions host. Conversely, as compute demand is reduced, the scale controller removes function host instances. The number of instances is eventually “scaled in” to zero when no functions are running within a function app.
Scaling behaviors
Scaling can vary on a number of factors, and scale differently based on the trigger and language selected. There are a few intricacies of scaling behaviors to be aware of:
Maximum instances: A single function app only scales out to a maximum of 200 instances. A single instance may process more than one message or request at a time though, so there isn’t a set limit on number of concurrent executions.
New instance rate: For HTTP triggers, new instances are allocated, at most, once per second. For non-HTTP triggers, new instances are allocated, at most, once every 30 seconds. Scaling is faster when running in a Premium plan.
Limit scale out
You may wish to restrict the maximum number of instances an app used to scale out. This is most common for cases where a downstream component like a database has limited throughput. By default, Consumption plan functions scale out to as many as 200 instances, and Premium plan functions will scale out to as many as 100 instances. You can specify a lower maximum for a specific app by modifying the value. The can be set to or for unrestricted, or a valid value between and the app maximum.
Knowledge check
Which of the following Azure Functions hosting plans is best when predictive scaling and costs are required?
App service plan
An organization wants to implement a serverless workflow to solve a business problem. One of the requirements is the solution needs to a designer-first (declarative) development model. Which of the choices below meets the requirements?
Azure Logic Apps
Develop Azure Functions
Explore Azure Functions development
A function contains two important pieces - your code, which can be written in a variety of languages, and some config, the function.json file. For compiled languages, this config file is generated automatically from annotations in your code. For scripting languages, you must provide the config file yourself.
The function.json file defines the function’s trigger, bindings, and other configuration settings. Every function has one and only one trigger. The runtime uses this config file to determine the events to monitor and how to pass data into and return data from a function execution. The following is an example function.json file.
1 | { |
Function app
A function app provides an execution context in Azure in which your functions run. As such, it is the unit of deployment and management for your functions. A function app is comprised of one or more individual functions that are managed, deployed, and scaled together.
Folder structure
The code for all the functions in a specific function app is located in a root project folder that contains a host configuration file. The host.json file contains runtime-specific configurations and is in the root folder of the function app. A bin folder contains packages and other library files that the function app requires.
Local development environments
Functions makes it easy to use your favorite code editor and development tools to create and test functions on your local computer. Your local functions can connect to live Azure services, and you can debug them on your local computer using the full Functions runtime.
Create triggers and bindings
Triggers are what cause a function to run. A trigger defines how a function is invoked and a function must have exactly one trigger. Triggers have associated data, which is often provided as the payload of the function.
Binding to a function is a way of declaratively connecting another resource to the function; bindings may be connected as input bindings, output bindings, or both. Data from bindings is provided to the function as parameters.
Trigger and binding definitions
| Language | Triggers and bindings are configured by… |
|---|---|
| C# class library | decorating methods and parameters with C# attributes |
| Java | decorating methods and parameters with Java annotations |
| JavaScript/PowerShell/Python/TypeScript | updating function.json schema |
For languages that rely on function.json, the portal provides a UI for adding bindings in the Integration tab. You can also edit the file directly in the portal in the Code + test tab of your function.
In .NET and Java, the parameter type defines the data type for input data. For instance, use to bind to the text of a queue trigger, a byte array to read as binary, and a custom type to de-serialize to an object. Since .NET class library functions and Java functions don’t rely on function.json for binding definitions, they can’t be created and edited in the portal. C# portal editing is based on C# script, which uses function.json instead of attributes.
For languages that are dynamically typed such as JavaScript, use the property in the function.json file. For example, to read the content of an HTTP request in binary format, set to :
1 | { |
Binding direction
All triggers and bindings have a direction property in the function.json file:
- For triggers, the direction is always
in - Input and output bindings use and
in out - Some bindings support a special direction . If you use , only the Advanced editor is available via the Integrate tab in the portal.
inout
Azure Functions trigger and binding example
Suppose you want to write a new row to Azure Table storage whenever a new message appears in Azure Queue storage. This scenario can be implemented using an Azure Queue storage trigger and an Azure Table storage output binding.
Here’s a function.json file for this scenario.
1 | { |
C# script example
Here’s C# script code that works with this trigger and binding.
1 |
|
JavaScript example
1 | // From an incoming queue message that is a JSON object, add fields and write to Table Storage |
Class library example
1 | public static class QueueTriggerTableOutput |
Connect functions to Azure services
Your function project references connection information by name from its configuration provider. It does not directly accept the connection details, allowing them to be changed across environments. For example, a trigger definition might include a connection property. This might refer to a connection string, but you cannot set the connection string directly in a function.json. Instead, you would set connection to the name of an environment variable that contains the connection string.
The default configuration provider uses environment variables. These might be set by Application Settings when running in the Azure Functions service, or from the local settings file when developing locally.
Knowledge check
Which of the following is required for a function to run?
Trigger
Which of the following supports both the in and out direction settings?
Bindings
Implement Durable Functions
Explore Durable Functions app patterns
The durable functions extension lets you define stateful workflows by writing orchestrator functions and stateful entities by writing entity functions using the Azure Functions programming model.
Application patterns
The primary use case for Durable Functions is simplifying complex, stateful coordination requirements in serverless applications. The following sections describe typical application patterns that can benefit from Durable Functions:
- Function chaining: In the function chaining pattern, a sequence of functions executes in a specific order.

- Fan-out/fan-in: In the fan out/fan in pattern, you execute multiple functions in parallel and then wait for all functions to finish.
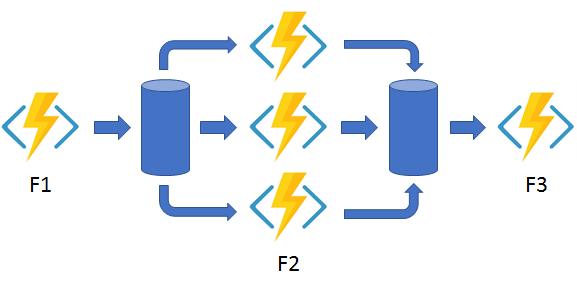
- Async HTTP APIs: The async HTTP API pattern addresses the problem of coordinating the state of long-running operations with external clients. A common way to implement this pattern is by having an HTTP endpoint trigger the long-running action. Then, redirect the client to a status endpoint that the client polls to learn when the operation is finished.

- Monitor: The monitor pattern refers to a flexible, recurring process in a workflow. An example is polling until specific conditions are met.

- Human interaction: Involving humans in an automated process is tricky because people aren’t as highly available and as responsive as cloud services. An automated process might allow for this interaction by using timeouts and compensation logic.

Discover the four function types
There are currently four durable function types in Azure Functions: orchestrator, activity, entity, and client.
Orchestrator functions
Orchestrator functions describe how actions are executed and the order in which actions are executed.
Activity functions
Activity functions are the basic unit of work in a durable function orchestration. For example, you might create an orchestrator function to process an order. The tasks involve checking the inventory, charging the customer, and creating a shipment. Each task would be a separate activity function. These activity functions may be executed serially, in parallel, or some combination of both.
Unlike orchestrator functions, activity functions aren’t restricted in the type of work you can do in them. Activity functions are frequently used to make network calls or run CPU intensive operations. An activity function can also return data back to the orchestrator function.
Entity functions
Entity functions define operations for reading and updating small pieces of state. We often refer to these stateful entities as durable entities. Like orchestrator functions, entity functions are functions with a special trigger type, entity trigger. They can also be invoked from client functions or from orchestrator functions. Unlike orchestrator functions, entity functions do not have any specific code constraints.
Client functions
Orchestrator and entity functions are triggered by their bindings and both of these triggers work by reacting to messages that are enqueued in a task hub. The primary way to deliver these messages is by using an orchestrator client binding, or an entity client binding, from within a client function. Any non-orchestrator function can be a client function. For example, You can trigger the orchestrator from an HTTP-triggered function, an Azure Event Hub triggered function, etc. What makes a function a client function is its use of the durable client output binding.
Unlike other function types, orchestrator and entity functions cannot be triggered directly using the buttons in the Azure portal. If you want to test an orchestrator or entity function in the Azure portal, you must instead run a client function that starts an orchestrator or entity function as part of its implementation. For the simplest testing experience, a manual trigger function is recommended.
Explore task hubs
A task hub in Durable Functions is a logical container for durable storage resources that are used for orchestrations and entities. Orchestrator, activity, and entity functions can only directly interact with each other when they belong to the same task hub.
If multiple function apps share a storage account, each function app must be configured with a separate task hub name. A storage account can contain multiple task hubs. This restriction generally applies to other storage providers as well.
Explore durable orchestrations
You can use an orchestrator function to orchestrate the execution of other Durable functions within a function app. Orchestrator functions have the following characteristics:
- Orchestrator functions define function workflows using procedural code. No declarative schemas or designers are needed.
- Orchestrator functions can call other durable functions synchronously and asynchronously. Output from called functions can be reliably saved to local variables.
- Orchestrator functions are durable and reliable. Execution progress is automatically checkpointed when the function “awaits” or “yields”. Local state is never lost when the process recycles or the VM reboots.
- Orchestrator functions can be long-running. The total lifespan of an orchestration instance can be seconds, days, months, or never-ending.
Reliability
Orchestrator functions reliably maintain their execution state by using the event sourcing design pattern. Instead of directly storing the current state of an orchestration, the Durable Task Framework uses an append-only store to record the full series of actions the function orchestration takes.
Control timing in Durable Functions
Durable Functions provides durable timers for use in orchestrator functions to implement delays or to set up timeouts on async actions. Durable timers should be used in orchestrator functions instead of Thread.Sleep and Task.Delay (C#), or setTimeout() and setInterval() (JavaScript), or time.sleep() (Python).
You create a durable timer by calling the CreateTimer (.NET) method or the createTimer (JavaScript) method of the orchestration trigger binding. The method returns a task that completes on a specified date and time.
Send and wait for events
Orchestrator functions have the ability to wait and listen for external events. This feature of Durable Functions is often useful for handling human interaction or other external triggers.
Knowledge check
Which of the following durable function types is used to read and update small pieces of state?
Entity
Which application pattern would you use for a durable function that is polling a resource until a specific condition is met?
Monitor
Explore Azure Cosmos DB
Introduction
Azure Cosmos DB is a globally distributed database system that allows you to read and write data from the local replicas of your database and it transparently replicates the data to all the regions associated with your Cosmos account.
Identify key benefits of Azure Cosmos DB
With Azure Cosmos DB, you can add or remove the regions associated with your account at any time. Your application doesn’t need to be paused or redeployed to add or remove a region.
Key benefits of global distribution
Your application can perform near real-time reads and writes against all the regions you chose for your database. Azure Cosmos DB internally handles the data replication between regions with consistency level guarantees of the level you’ve selected.
Running a database in multiple regions worldwide increases the availability of a database. If one region is unavailable, other regions automatically handle application requests.
Explore the resource hierarchy
Elements in an Azure Cosmos account
The following image shows the hierarchy of different entities in an Azure Cosmos DB account:
Azure Cosmos databases
You can create one or multiple Azure Cosmos databases under your account. A database is analogous to a namespace. A database is the unit of management for a set of Azure Cosmos containers.
Azure Cosmos containers
An Azure Cosmos container is the unit of scalability both for provisioned throughput and storage. A container is horizontally partitioned and then replicated across multiple regions. The items that you add to the container are automatically grouped into logical partitions, which are distributed across physical partitions, based on the partition key.
When you create a container, you configure throughput in one of the following modes:
Dedicated provisioned throughput mode: The throughput provisioned on a container is exclusively reserved for that container and it is backed by the SLAs.
Shared provisioned throughput mode: These containers share the provisioned throughput with the other containers in the same database (excluding containers that have been configured with dedicated provisioned throughput). In other words, the provisioned throughput on the database is shared among all the “shared throughput” containers.
Explore consistency levels
Azure Cosmos DB approaches data consistency as a spectrum of choices instead of two extremes. Strong consistency and eventual consistency are at the ends of the spectrum, but there are many consistency choices along the spectrum.
With Azure Cosmos DB, developers can choose from five well-defined consistency models on the consistency spectrum. From strongest to more relaxed, the models include:
- strong
- bounded staleness
- session
- consistent prefix
- eventual
Choose the right consistency level
SQL API and Table API
Consider the following points if your application is built using SQL API or Table API:
For many real-world scenarios, session consistency is optimal and it’s the recommended option.
If your application requires strong consistency, it is recommended that you use bounded staleness consistency level.
If you need stricter consistency guarantees than the ones provided by session consistency and single-digit-millisecond latency for writes, it is recommended that you use bounded staleness consistency level.
If your application requires eventual consistency, it is recommended that you use consistent prefix consistency level.
If you need less strict consistency guarantees than the ones provided by session consistency, it is recommended that you use consistent prefix consistency level.
If you need the highest availability and the lowest latency, then use eventual consistency level.
If you need even higher data durability without sacrificing performance, you can create a custom consistency level at the application layer.
Explore supported APIs
Azure Cosmos DB offers multiple database APIs, which include the Core (SQL) API, API for MongoDB, Cassandra API, Gremlin API, and Table API. By using these APIs, you can model real world data using documents, key-value, graph, and column-family data models. These APIs allow your applications to treat Azure Cosmos DB as if it were various other databases technologies, without the overhead of management, and scaling approaches.
Discover request units
With Azure Cosmos DB, you pay for the throughput you provision and the storage you consume on an hourly basis. Throughput must be provisioned to ensure that sufficient system resources are available for your Azure Cosmos database at all times.
The cost of all database operations is normalized by Azure Cosmos DB and is expressed by request units (or RUs, for short). A request unit represents the system resources such as CPU, IOPS, and memory that are required to perform the database operations supported by Azure Cosmos DB.
The cost to do a point read, which is fetching a single item by its ID and partition key value, for a 1KB item is 1RU. All other database operations are similarly assigned a cost using RUs. No matter which API you use to interact with your Azure Cosmos container, costs are always measured by RUs. Whether the database operation is a write, point read, or query, costs are always measured in RUs.
The type of Azure Cosmos account you’re using determines the way consumed RUs get charged. There are three modes in which you can create an account:
Provisioned throughput mode: In this mode, you provision the number of RUs for your application on a per-second basis in increments of 100 RUs per second. To scale the provisioned throughput for your application, you can increase or decrease the number of RUs at any time in increments or decrements of 100 RUs. You can make your changes either programmatically or by using the Azure portal. You can provision throughput at container and database granularity level.
Serverless mode: In this mode, you don’t have to provision any throughput when creating resources in your Azure Cosmos account. At the end of your billing period, you get billed for the amount of request units that has been consumed by your database operations.
Autoscale mode: In this mode, you can automatically and instantly scale the throughput (RU/s) of your database or container based on it’s usage. This mode is well suited for mission-critical workloads that have variable or unpredictable traffic patterns, and require SLAs on high performance and scale.
Knowledge check
When setting up Azure Cosmos DB there are three account type options. Which of the account type options below is used to specify the number of RUs for an application on a per-second basis?
Provisioned throughput
Which of the following consistency levels below offers the greatest throughput?
Eventual(The eventual consistency level offers the greatest throughput at the cost of weaker consistency.)
Implement partitioning in Azure Cosmos DB
Explore partitions
In partitioning, the items in a container are divided into distinct subsets called logical partitions. Logical partitions are formed based on the value of a partition key that is associated with each item in a container. All the items in a logical partition have the same partition key value.
Logical partitions
A logical partition consists of a set of items that have the same partition key. For example, in a container that contains data about food nutrition, all items contain a property. You can use as the partition key for the container.
Physical partitions
A container is scaled by distributing data and throughput across physical partitions. Internally, one or more logical partitions are mapped to a single physical partition. Typically smaller containers have many logical partitions but they only require a single physical partition. Unlike logical partitions, physical partitions are an internal implementation of the system and they are entirely managed by Azure Cosmos DB.
The number of physical partitions in your container depends on the following:
The number of throughput provisioned (each individual physical partition can provide a throughput of up to 10,000 request units per second). The 10,000 RU/s limit for physical partitions implies that logical partitions also have a 10,000 RU/s limit, as each logical partition is only mapped to one physical partition.
The total data storage (each individual physical partition can store up to 50GB data).
Choose a partition key
A partition key has two components: partition key path and the partition key value.
For example, consider an item { “userId” : “Andrew”, “worksFor”: “Microsoft” } if you choose “userId” as the partition key, the following are the two partition key components:
The partition key path (for example: “/userId”). The partition key path accepts alphanumeric and underscore(_) characters. You can also use nested objects by using the standard path notation(/).
The partition key value (for example: “Andrew”). The partition key value can be of string or numeric types.
For all containers, your partition key should:
Be a property that has a value which does not change. If a property is your partition key, you can’t update that property’s value.
Have a high cardinality. In other words, the property should have a wide range of possible values.
Spread request unit (RU) consumption and data storage evenly across all logical partitions. This ensures even RU consumption and storage distribution across your physical partitions.
Create a synthetic partition key
It’s the best practice to have a partition key with many distinct values, such as hundreds or thousands. The goal is to distribute your data and workload evenly across the items associated with these partition key values. If such a property doesn’t exist in your data, you can construct a synthetic partition key.
This unit describes several basic techniques for generating a synthetic partition key for your Cosmos container.
- Concatenate multiple properties of an item
- Use a partition key with a random suffix
- Use a partition key with pre-calculated suffixes
Knowledge check
Which of the options below best describes the relationship between logical and physical partitions?
Physical partitions are collections of logical partitions
Which of the below correctly lists the two components of a partition key?
Key path, key value
Work with Azure Cosmos DB
Manage the Azure Blob storage lifecycle
React to state changes in your Azure services by using Event Grid
In a complex cloud environment, you might need to respond to events from many different sources both automatically and manually.
Suppose you work on an operations team for a large healthcare organization. You have a system with virtual machines that are under strict regulatory and change control. You want to be notified of any changes to the configuration of these virtual machines in Azure by email. To accomplish this, you’ll use Azure Event Grid to receive events that happen to virtual machines and Azure Logic Apps to send emails that alert your team of any changes.
Respond to Azure events by using Event Grid
What is Event Grid?
Event Grid aggregates all your events and provides routing from any source to any destination. Event Grid is a service that manages the routing and delivery of events from many sources and subscribers. This process eliminates the need for polling, and results in minimized cost and latency.
Event publishers and subscribers are decoupled by using the publisher/subscriber pattern.
Event sources and event handlers
Sources can be configured from anywhere, and include on-premises custom applications or virtual machines within your Azure account. A source allows a single mechanism for event management through all your systems, whether they’re in an on-premises datacenter or with other cloud providers.
Topics and event subscriptions
When the topics have been defined, you can subscribe to them. Subscriptions convey which events on a topic you’re interested in receiving. These events can then be filtered by type or subject.
Subscribe to events
You can use the Azure Logic Apps Designer service as an example subscriber. A logic app is a way of scheduling or orchestrating tasks. It’s a solution that you use to orchestrate a set of jobs when a trigger is run.
Configure connectors and triggers
After creating an event handler that deals with an event, you can configure the connectors and triggers associated to it.
Exercise - Trigger a logic app by using Event Grid
- Create a virtual machine
- Create a logic app
- Add an Event Grid trigger to the logic app
Build logic that responds to an event
learn how to create actions and conditions to respond to events